Convolutional Matrix Factorization for
Document Context-Aware Recommendation
Abstract
Sparseness of user-to-item rating data is one of the major factors that deteriorate the quality of recommender system. To handle the sparsity problem, several recommendation techniques have been proposed that additionally consider auxiliary information to improve rating prediction accuracy. In particular, when rating data is sparse, document modeling-based approaches have improved the accuracy by additionally utilizing textual data such as reviews, abstracts, or synopses. However, due to the inherent limitation of the bag-of-words model, they have difficulties in effectively utilizing contextual information of the documents, which leads to shallow understanding of the documents. This paper proposes a novel context-aware recommendation model, convolutional matrix factorization (ConvMF) that integrates convolutional neural network (CNN) into probabilistic matrix factorization (PMF). Consequently, ConvMF captures contextual information of documents and further enhances the rating prediction accuracy. Our extensive evaluations on three real-world datasets show that ConvMF significantly outperforms the state-of-the-art recommendation models even when the rating data is extremely sparse. We also demonstrate that ConvMF successfully captures subtle contextual difference of a word in a document.
Overview

Experiments
Datasets
1. Data Statistics:
| Dataset | # users | # items | # ratings | density |
|---|---|---|---|---|
| MovieLens-1m (ML-1m) | 6,040 | 3,544 | 993,482 | 4.641% |
| MovieLens-10m (ML-10m) | 69,878 | 10,073 | 9,945,875 | 1.413% |
| Amazon Instant Video (AIV) | 29,757 | 15,149 | 135,188 | 0.030% |
2. Data Skewness:


Competitors
| Model | Description |
|---|---|
| Probabilistic Matrix Factorization (PMF) [Salakhutdinov et al.] |
A standard rating prediction model that only uses ratings for collaborative filtering. |
| Collaborative Topic Regression (CTR) [Wang et al.] |
A state-of-the-art recommendation model that combines collaborative filtering (PMF) and topic modeling (LDA) to use both ratings and documents. |
| Collaborative Deep Learning (CDL) [Wang et al.] |
Another state-of-the-art recommendation model that enhances rating prediction accuracy by analyzing documents using stacked denoising auto-encoder (SDAE). |
| Convolutional Matrix Factorization (ConvMF) | Our proposed model. |
| Convolutional Matrix Factorization with a pre-trained word embedding model (ConvMF+) | Another version of our proposed model, and we use Glove [Pennington et al.] for the pre-trained word embedding model. |
Results
If you want to know more detailed explanation, please refer to our paper
1. Overall test RMSE with SD:
| Model | Dataset | ||
|---|---|---|---|
| ML-1m | ML-10m | AIV | |
| PMF | 0.8971 (0.0020) | 0.8311 (0.0010) | 1.4118 (0.0105) |
| CTR | 0.8969 (0.0027) | 0.8275 (0.0004) | 1.5496 (0.0104) |
| CDL | 0.8879 (0.0015) | 0.8186 (0.0005) | 1.3594 (0.0139) |
| ConvMF | 0.8531 (0.0018) | 0.7958 (0.0006) | 1.1337 (0.0043) |
| ConvMF+ | 0.8549 (0.0018) | 0.7930 (0.0006) | 1.1279 (0.0073) |
| Improve | 3.92% | 2.79% | 16.60% |
Above table shows the overall rating prediction errors of five methods on each test set. Note that each dataset is randomly split into a training set (80%), a validation set (10%), and a test set (10%). "Improve" indicates the relative improvements of "ConvMF" over the the best competitor. Compared to three models, ConvMF and ConvMF+ achieve significant improvements on all the datasets.
2. Test RMSE over various sparseness of training data on ML-1m dataset:
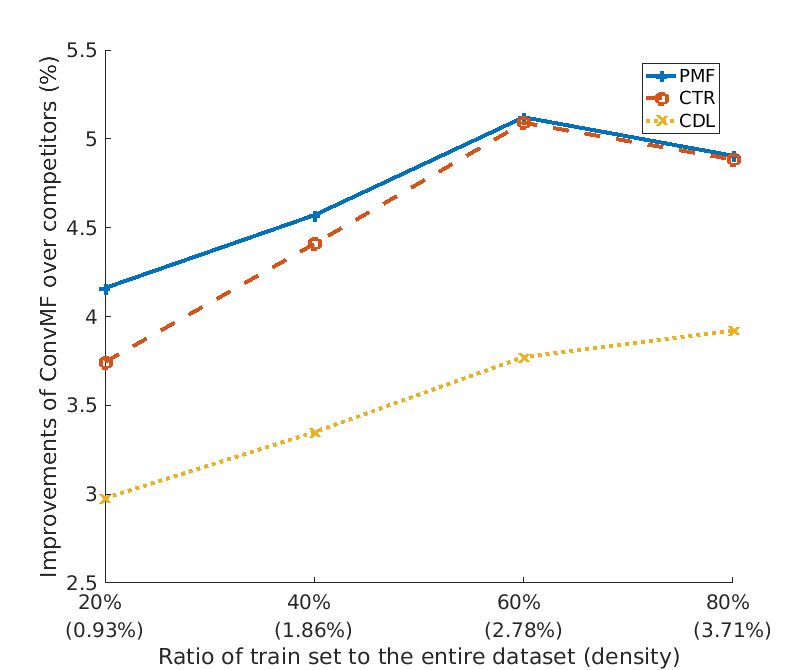
This plot shows improvements of ConvMF on three competitors over various spaseness datasets. ConvMF significantly outperforms three competitors over all range over sparseness, and we can see that when the data density increases, the improvements increase. It indicates that CNN of ConvMF is well integrated into PMF for recommendation task to exploit rating information.
3. Impact of Pre-trained Word Embedding Model:
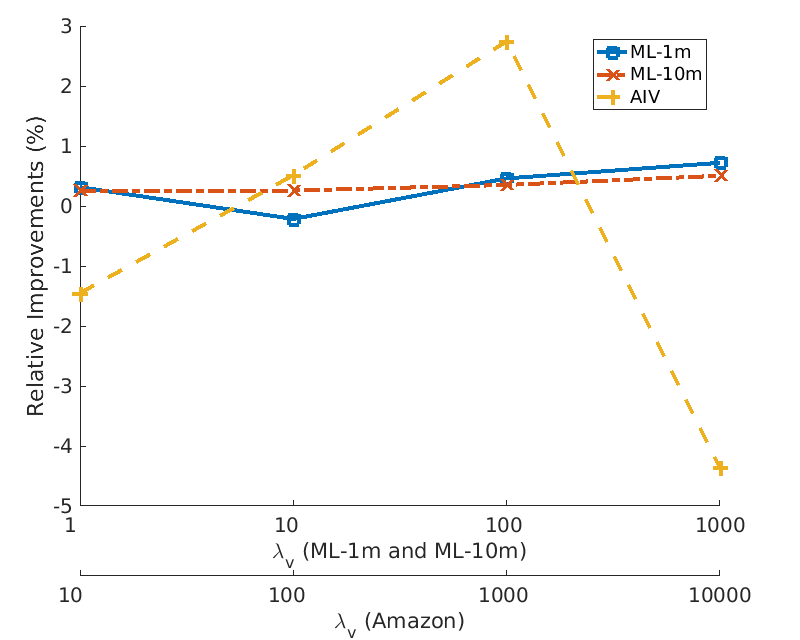
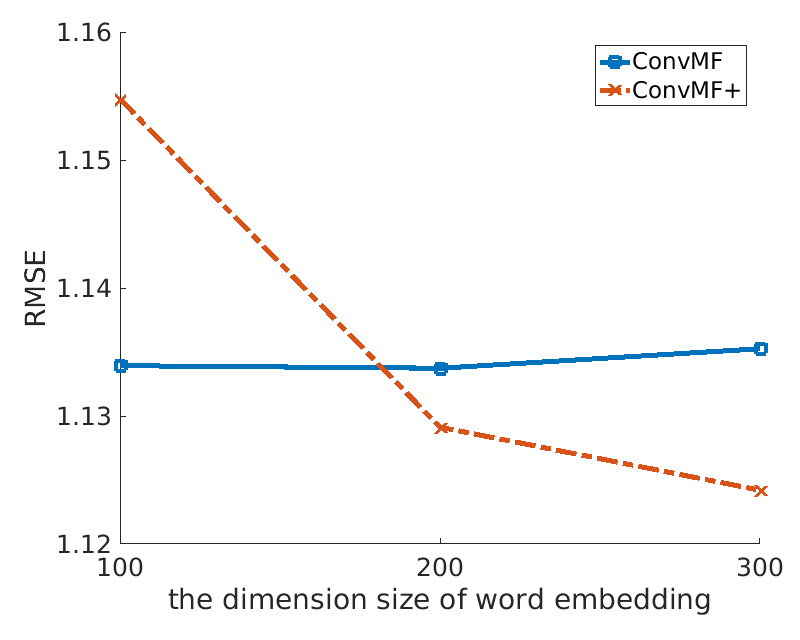
Two plots introduce impacts of pre-trained word embedding model for ConvMF. Left plot shows relative improvements of ConvMF+ over ConvMF on three datasets with various λv. As data is more extremely skewed (i.e. Amazon Instant Video), an impact of pre-trained word embedding model increases. Note that a high value of λv leads that ConvMF and ConvMF+ try to exploit description documents of items more than ratings. Right plot shows the effects of the dimension size of word embedding model on Amazon Instant Video dataset. The test error of ConvMF+ is decreased as the dimension size of the pre-trained word embedding model gets higher, because the information contained in the model gets richer.
4. Parameter Analysis:

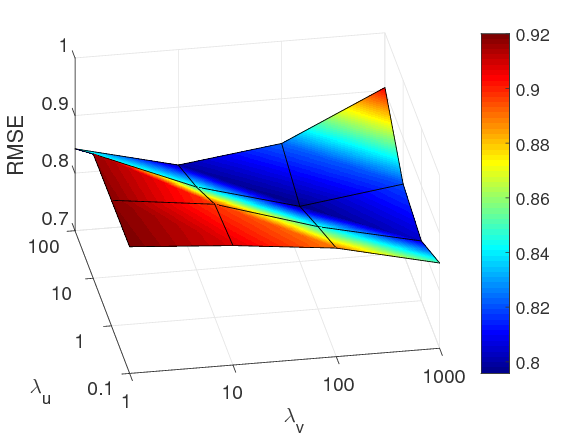
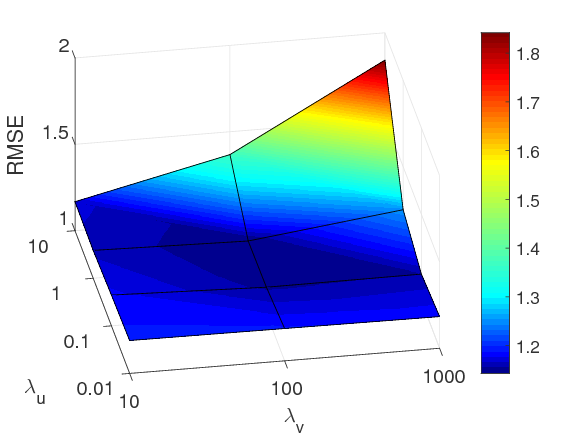
Three figures shows impacts of λu and λv on three datasets. Specifically, the best performing values of (λu, λv) of ConvMF are (100, 10), (10, 100), and (1, 100) on MovieLens-1m, MovieLens-10m and Amazon Instant Video, respectively. A high value of λu implies that item latnet model tend to be projeted to the latent space of user latent model (same applies to λv). Thus, these best performing values demonstrate that ConvMF well alleviates sparseness of each dataset by balancing the importance of ratings and description documents. Note that a sparse dataset requires high value of λv.
5. Qualitative Analysis:
| Phrase captured by Wc11 | max(c11) | Phrase captured by Wc86 | max(c86) |
|---|---|---|---|
| people trust the man | 0.0704 | betray his trust finally | 0.1009 |
| Test phrases for Wc11 | max(ctest11) | Test phrases for Wc86 | max(ctest86) |
| people believe the man | 0.0391 | betray his believe finally | 0.0682 |
| people faith the man | 0.0374 | betray his faith finally | 0.0693 |
| people tomas the man | 0.0054 | betray his tomas finally | 0.0480 |
This table verifies whether ConvMF is able to distinguish subtle contextual differences by comparing each contextual meanings of phrases captured by the shared weights of CNN. Specifically, as a case study, we selected Wc11 and Wc86 from the model trained on ML-10m dataset, and compared the contextual meaning of phrases captured by the shared weights. The meaning of “trust” in the two phrases captured by the two shared weights seem to be similar to each other. However, there is a subtle difference on contextual meaning of the term “trust” in the two phrases. Indeed, the “trust” in the phrase captured by Wc11 is used as a verb whereas the “trust” in the phrase captured by Wc86 is used as a noun. A higher context feature value has more chance to be selected in order to affect the performance of ConvMF, and we can see that ConvMF distinguishes a subtle contextual difference of the term "trust".
Code & Data
- Our code is here [Github].
- Datasets [MovieLens and Amazon Instant Video] are movielens, aiv.